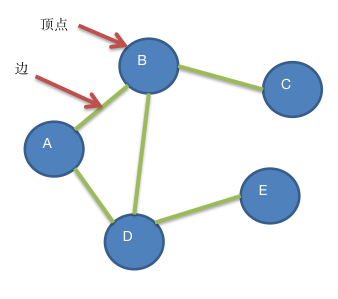
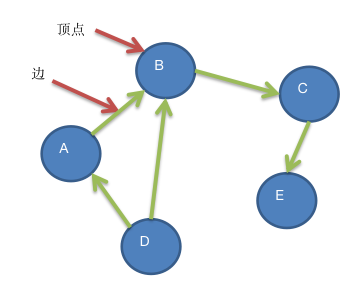
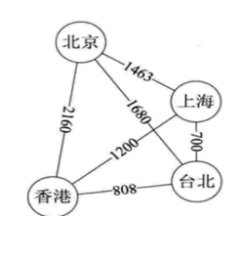
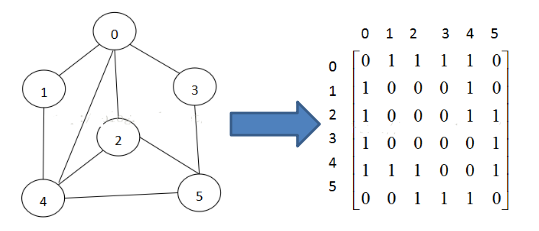
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
| package com.guizimo;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
public class Graph {
private ArrayList<String> vertexList;
private int[][] edges;
private int numOfEdges;
private boolean[] isVisited;
public static void main(String[] args) {
int n = 8;
String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};
Graph graph = new Graph(n);
for(String vertex: Vertexs) {
graph.insertVertex(vertex);
}
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
graph.showGraph();
System.out.println("广度优先遍历
graph.dfs();
System.out.println("深度优先遍历
graph.bfs();
}
public Graph(int n) {
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
}
public int getFirstNeighbor(int index) {
for(int j = 0; j < vertexList.size(); j++) {
if(edges[index][j] > 0) {
return j;
}
}
return -1;
}
public int getNextNeighbor(int v1, int v2) {
for(int j = v2 + 1; j < vertexList.size(); j++) {
if(edges[v1][j] > 0) {
return j;
}
}
return -1;
}
private void dfs(boolean[] isVisited, int i) {
System.out.print(getValueByIndex(i) + "->");
isVisited[i] = true;
int w = getFirstNeighbor(i);
while(w != -1) {
if(!isVisited[w]) {
dfs(isVisited, w);
}
w = getNextNeighbor(i, w);
}
}
public void dfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
private void bfs(boolean[] isVisited, int i) {
int u ;
int w ;
LinkedList queue = new LinkedList();
System.out.print(getValueByIndex(i) + "=>");
isVisited[i] = true;
queue.addLast(i);
while( !queue.isEmpty()) {
u = (Integer)queue.removeFirst();
w = getFirstNeighbor(u);
while(w != -1) {
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
isVisited[w] = true;
queue.addLast(w);
}
w = getNextNeighbor(u, w);
}
}
}
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
public int getNumOfVertex() {
return vertexList.size();
}
public void showGraph() {
for(int[] link : edges) {
System.err.println(Arrays.toString(link));
}
}
public int getNumOfEdges() {
return numOfEdges;
}
public String getValueByIndex(int i) {
return vertexList.get(i);
}
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
}
|